| | |
|---|
| | | # 语音合成与识别服务Docker-部署说明 |
|---|
| | | <style> |
|---|
| | | pre, code { |
|---|
| | | white-space: pre-wrap; |
|---|
| | | word-break: break-all; |
|---|
| | | } |
|---|
| | | </style> |
|---|
| | | |
|---|
| | | ## 一、简介 |
|---|
| | | 语音合成与识别服务(以下简称“服务”)提供高质量的文本转语音(TTS)和语音转文本(ASR)功能。为了方便用户快速部署和使用该服务,我们提供了基于Docker的部署方案。本文档将详细介绍如何使用Docker部署该服务。 |
|---|
| | | 本文提供的语音合成与识别服务,是基于paddlespeech开发的TTS和ASR服务(纯CPU服务),用户可以通过Docker快速部署并使用该服务。 |
|---|
| | | |
|---|
| | | ## 二、环境准备 |
|---|
| | | 在开始部署之前,请确保您的环境满足以下要求: |
|---|
| | | 1. 已安装Docker和Docker Compose。 |
|---|
| | | 2. 具备一定的Linux命令行操作基础。 |
|---|
| | | 3. 确保您的服务器具备足够的计算资源(CPU、内存、GPU等)。 |
|---|
| | | |
|---|
| | | ## 三、获取Docker镜像 |
|---|
| | | 我们提供了预构建的Docker镜像,地址位于七牛云,地址为: |
|---|
| | | |
|---|
| | | 我们提供了预构建的Docker镜像,地址位于七牛云,[下载地址](https://datacdn.data-it.tech/HomeAssistant/dokerimages/paddlespeech1.1/paddlespeech.tar)为: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | https://datacdn.data-it.tech/HomeAssistant/dokerimages/paddlespeech1.1/paddlespeech.tar |
|---|
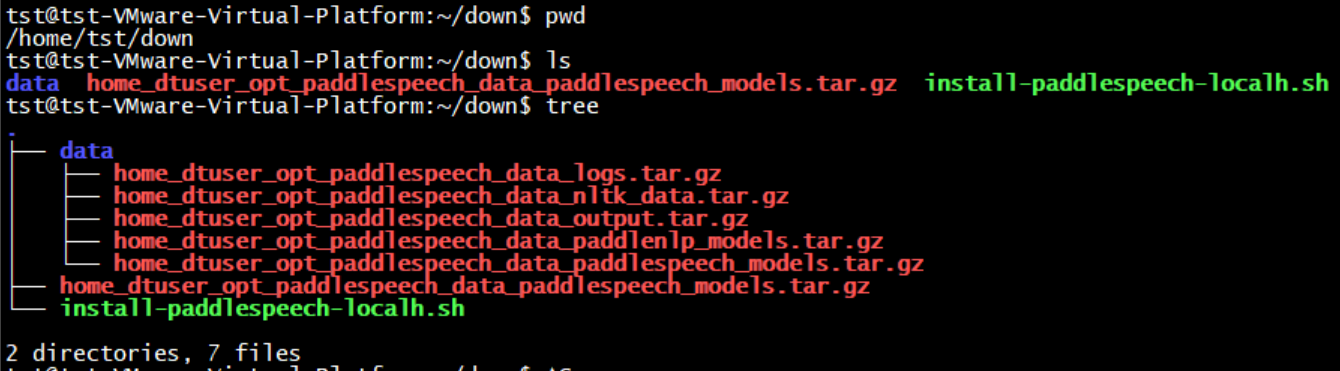
| | |
|---|
| | | │ ├── home_dtuser_opt_paddlespeech_data_output.tar.gz |
|---|
| | | │ ├── home_dtuser_opt_paddlespeech_data_paddlenlp_models.tar.gz |
|---|
| | | │ └── home_dtuser_opt_paddlespeech_data_paddlespeech_models.tar.gz |
|---|
| | | ├── home_dtuser_opt_paddlespeech_data_paddlespeech_models.tar.gz |
|---|
| | | └── install-paddlespeech-localh.sh |
|---|
| | | |
|---|
| | | 2 directories, 6 files |
|---|
| | | 2 directories, 7 files |
|---|
| | | ``` |
|---|
| | |  |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | ### 2. 给运行脚本添加执行权限 |
|---|
| | | |
|---|

