From a7eb97fc18f24c13b3c79350b1941f429f41150b Mon Sep 17 00:00:00 2001
From: trphoenix <spd260@126.com>
Date: 星期四, 11 十二月 2025 15:42:44 +0800
Subject: [PATCH] vault backup: 2025-12-11 15:42:44
---
Help/docs/Usages/QA/语音合成与识别服务Docker-部署说明.md | 43 +++++++++++++++++++++++++++++++------------
1 files changed, 31 insertions(+), 12 deletions(-)
diff --git "a/Help/docs/Usages/QA/\350\257\255\351\237\263\345\220\210\346\210\220\344\270\216\350\257\206\345\210\253\346\234\215\345\212\241Docker-\351\203\250\347\275\262\350\257\264\346\230\216.md" "b/Help/docs/Usages/QA/\350\257\255\351\237\263\345\220\210\346\210\220\344\270\216\350\257\206\345\210\253\346\234\215\345\212\241Docker-\351\203\250\347\275\262\350\257\264\346\230\216.md"
index e30c74e..e371bac 100644
--- "a/Help/docs/Usages/QA/\350\257\255\351\237\263\345\220\210\346\210\220\344\270\216\350\257\206\345\210\253\346\234\215\345\212\241Docker-\351\203\250\347\275\262\350\257\264\346\230\216.md"
+++ "b/Help/docs/Usages/QA/\350\257\255\351\237\263\345\220\210\346\210\220\344\270\216\350\257\206\345\210\253\346\234\215\345\212\241Docker-\351\203\250\347\275\262\350\257\264\346\230\216.md"
@@ -1,15 +1,24 @@
# 语音合成与识别服务Docker-部署说明
+<style>
+pre, code {
+ white-space: pre-wrap;
+ word-break: break-all;
+}
+</style>
## 一、简介
语音合成与识别服务(以下简称“服务”)提供高质量的文本转语音(TTS)和语音转文本(ASR)功能。为了方便用户快速部署和使用该服务,我们提供了基于Docker的部署方案。本文档将详细介绍如何使用Docker部署该服务。
本文提供的语音合成与识别服务,是基于paddlespeech开发的TTS和ASR服务(纯CPU服务),用户可以通过Docker快速部署并使用该服务。
+
## 二、环境准备
在开始部署之前,请确保您的环境满足以下要求:
1. 已安装Docker和Docker Compose。
2. 具备一定的Linux命令行操作基础。
3. 确保您的服务器具备足够的计算资源(CPU、内存、GPU等)。
+
## 三、获取Docker镜像
-我们提供了预构建的Docker镜像,地址位于七牛云,地址为:
+
+我们提供了预构建的Docker镜像,地址位于七牛云,[下载地址](https://datacdn.data-it.tech/HomeAssistant/dokerimages/paddlespeech1.1/paddlespeech.tar)为:
```
https://datacdn.data-it.tech/HomeAssistant/dokerimages/paddlespeech1.1/paddlespeech.tar
@@ -37,11 +46,20 @@
```
docker logs -f paddlespeech
```
-TTS模型首次使用时侍自动从网络下载约2G的模型文件,下载完成后会自动启动服务。后续再次使用时,不会重复下载模型文件。
+容器启动后,先会载一个NLP的小模型,耗时约30秒左右,然后,启动服务与端口,
+当/tts这个api首次被调用时,容器的程序,会自动从网络下载约2G的模型文件,下载完成后会完成首次TTS输出,当然首次也有可能因网络超时失败。后续再次使用时,不会重复下载模型文件。
+
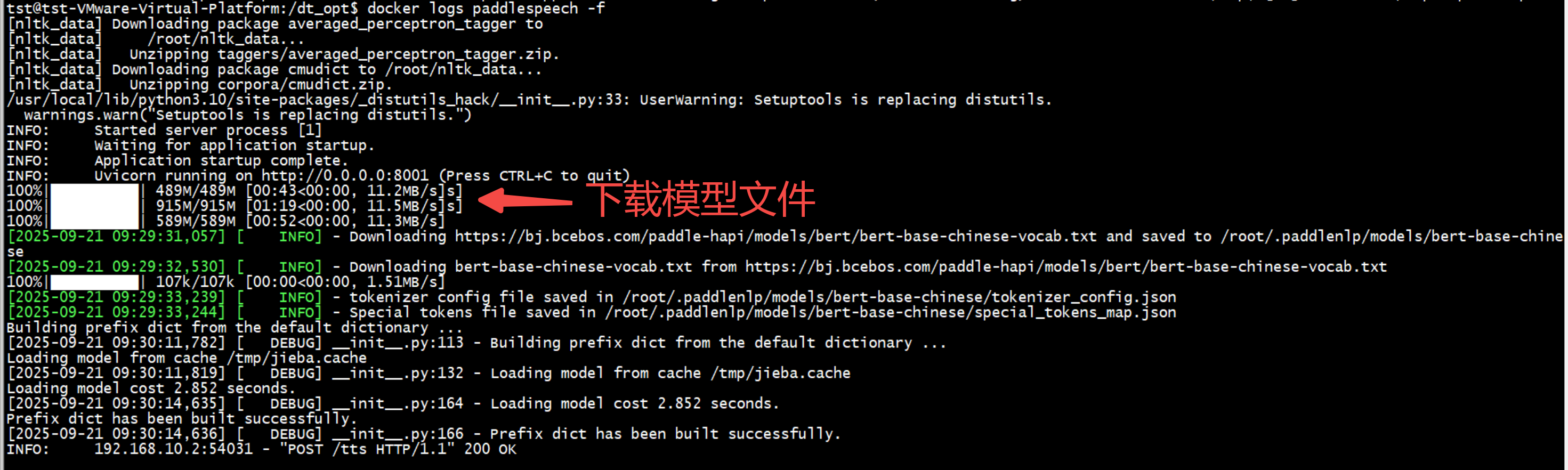
-Asr模型首次使用时侍自动从网络下载约1G的模型文件,下载完成后会自动启动服务。后续再次使用时,不会重复下载模型文件。
+
+当/asr这个api被首次调用时,容器中的程序会自动从网络下载约2G的模型文件,下载完成后会自动提供语音识别服务,并完成首次API识别的输出,当然,也有可能失败,后续再次调用此API是,不会重复下载模型文件。

+
+***上述下载过程较为缓慢,约5-10分钟左右,请耐心等待!如果想看实时过程,请输入:docker-comopose logs paddlespeech 来查看实时日志***
+
+***请在正式使用之前,用postman或文档中提供的测试网页,调试一次成功后,再放入后台运行!***
+
+
## 五、离线部署步骤
### 离线部署的相关文件下载地址
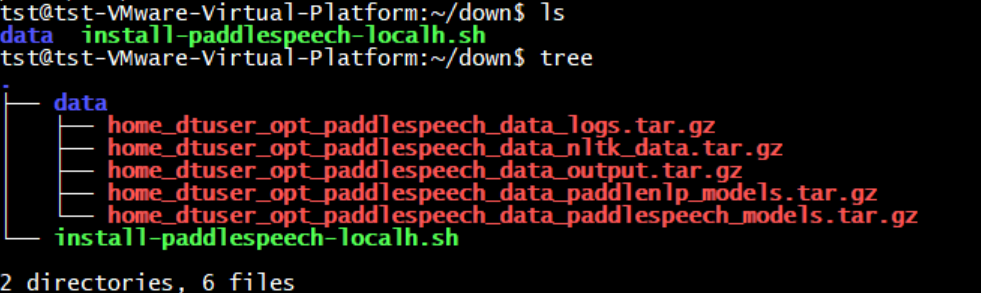
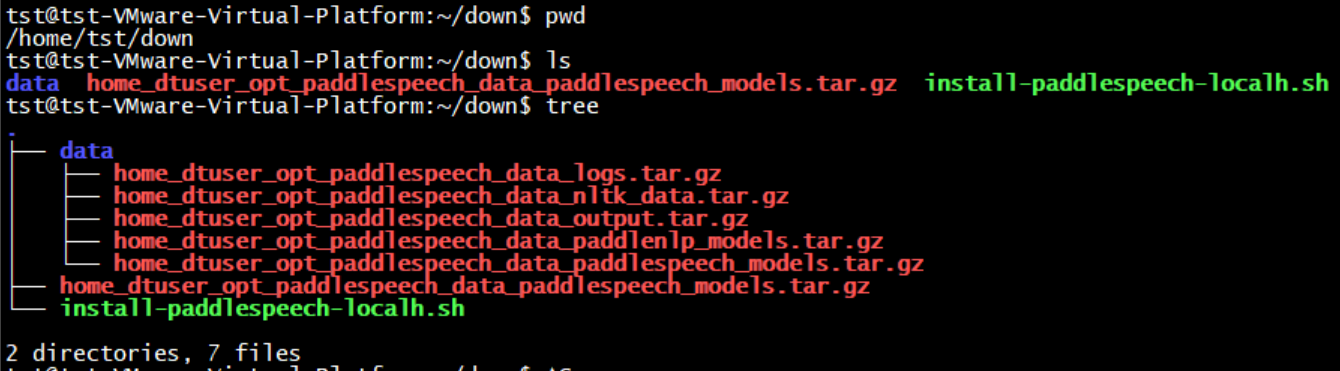
@@ -73,12 +91,13 @@
│ ├── home_dtuser_opt_paddlespeech_data_output.tar.gz
│ ├── home_dtuser_opt_paddlespeech_data_paddlenlp_models.tar.gz
│ └── home_dtuser_opt_paddlespeech_data_paddlespeech_models.tar.gz
+├── home_dtuser_opt_paddlespeech_data_paddlespeech_models.tar.gz
└── install-paddlespeech-localh.sh
-2 directories, 6 files
+2 directories, 7 files
```
-
-
+
+
### 2. 给运行脚本添加执行权限
@@ -242,12 +261,12 @@
```bash
-docker ps up -d # 启动容器
-docker ps down # 停止容器
-docker ps restart # 重启容器
-docker ps logs -f paddlespeech # 实时查看日志
-docker ps exec -it paddlespeech /bin/bash # 进入容器
-docker ps rm -f paddlespeech # 删除容器
+docker-compose up -d # 启动容器
+docker-compose down # 停止容器
+docker-compose restart paddlespeech # 重启容器
+docker logs -f paddlespeech # 实时查看日志
+docker exec -it paddlespeech /bin/bash # 进入容器
+docker rm -f paddlespeech # 删除容器
docker rmi dt_iot/paddlespeech:latest # 删除镜像
docker volume rm paddlespeech_data # 删除数据卷
docker network rm dtnet # 删除网络
--
Gitblit v1.8.0